Поглавје 6 Повторливи проекти
Во претходните две поглавја разгледавме како можеме нашиот едноставен код да го конвертираме во скрипта која ќе биде лесна за користење и до некоја мера издржлива во различни работни средини (Поглавје 4) и како да составиме повторлив извештај со повеќе табели и графици со помош на Rmd (Поглавје 5). Но како што напоменавме, сеуште правиме некои претпоставки за начинот на кој ќе биде користена скриптата и за ресурсите кои ќе им бидат достапни на корисниците. Една од овие претпоставки беше дека колегите кои ќе ја користат нашата скрипта ќе имаат адекватни табели за обработување. Ова е до некоја мера разумна претпоставка доколку скриптата се користи рамките на една организација, или доколку типот на табели кои ги обработува се доволно познати и распространети. Но ваквите случаи, иако значајни, претставуваат само дел инстанците кога треба да разговараме за повторливи анализи. Како што споменавме претходно во Секција 1.2 голем дел од сферата на статистички анализи, наука за податоци, и истражувања од било кое поле на науката се однесува на споделување на програмскиот код заедно со податоците, извештаите, презентациите, итн. Значи ни треба начин да го споделиме нашиот програмски код заедно со податоците кои ги обработуваме, инаку никој надвор од нашата организација нема да може да ја повтори анализата.
Во ова поглавје ќе се запознаеме со две стратегии за организирање на повторливи проекти. Првата стратегија (Направи сам) е едноставна за поставување и не зависи од дополнителна инфраструктура (додатни библиотеки), но ако проектот е комплексен, оваа опција може да бара повеќе грижа, особено за стабилност на подолг рок. Втората стратегија е да се повикаме на некоја веќе готова платформа за поставување на безбедна структура за повторливи проекти. Втората стратегија генерално треба да се преферира, но имајќи во предвид дека секој нов пакет си бара одреден период на запознавање и дека во некои случаи првата опција е сосема адекватна, ќе збориваме за двете стратегии.
6.1 Стратегија 1: Направи сам
6.1.1 Структура
Креирање безбедна структура за повторливост во основа е едноставно. Да речеме дека имаме извештај со два графикони и три табели, и дека секој график и табела се базирани на различни сетови на податоци. Имајќи ги во предвид нашите цели:
- да направиме што е можно помалку претпоставки за средината во којашто ќе биде повторена нашата анализа и
- да направиме што е можно полесно да се снајде некој без никакво претходно искуство со нашиот проект
можеме секој елемент од нашиот извештај да го енкапсулираме во посебен фолдер. Во секој фолдер мора да ги вклучиме податоците и програмскиот код коишто се неопходни за ре-креирање на графиконот или табелата. За детални објаснувања, можеме во (фали нешто тука?) да вклучиме README фалј во оние фолдери каде што е неопходно. Главен README фалј на првото ниво на нашиот проект мора да биде вклучен. Тука, го опишуваме нашиот проект, што подетално тоа подобро, и даваме објаснување за како да се користат податоците и кодот којшто е вклучен во субфолдерите. Ова е особено важно доколку скриптите зависат една од друга и треба да се извршат во некој редослед, на пример ако мора прво да го извршиме кодот во tabela_1 пред да можеме да работиме со tabela_2.
Во нашиот случај, со два графикони и три табели сите со различни податоци, би ја имаме следната структура:
strategija_1/
├── grafik_1
│ ├── code_grafik_1.R
│ └── data_grafik_1.csv
├── grafik_2
│ ├── code_grafik_2.R
│ └── data_grafik_2.csv
├── README
├── tabela_1
│ ├── code_tabela_1.R
│ └── data_tabela_1.csv
├── tabela_2
│ ├── code_tabela_2.R
│ └── data_tabela_2.csv
└── tabela_3
├── code_tabela_3.R
└── data_tabela_3.csvДоколку графиконите 1 и 2 се базирани на исти податоци како табелите 1 и 2, тогаш можеме да ги групираме, со што би избегнало непотребно копирање на истите податоци на две места:
strategija_1/
├── grafik_1
│ ├── code_grafik_1.R
│ ├── code_tabela_1.R
│ └── data_grafik_1.csv
├── grafik_2
│ ├── code_grafik_2.R
│ ├── code_tabela_2.R
│ └── data_grafik_2.csv
├── README
└── tabela_3
├── code_tabela_3.R
└── data_tabela_3.csvНо генерално, при одлучување за структурата на проектот треба да си го поставиме прашањето „како најлесно ќе се снајде некој што никогаш претходно нема работено со овие податоци или тип на анализи?“. Доколку одговорот на ова прашање сугерира да се копираат истите податоци на две места, и податоците се доволно мали да го дозволат тоа, тогаш е подобро да се направи вишокот отколку да се направи ре-анализата покомплицирана.
6.1.2 Предности
Како оваа стратегија овозможува повторливост? Доколку нашиот код ги следи принципите за кои збориваме претходно, спарувањето на податоците со кодот што треба да се користи за нивна обработка во еден фолдер изолирани од остатокот на проектот значи дека:
- шансите корисникот на нашиот проект да ги помеша фајловите се минимални,
- нашиот код може да биде поедноставен бидејќи вчитува податоци во истиот фолдер, и конечно
- сите резултати од извршувањето на нашиот код (на пример пдф од графикон) ќе се зачуваат во истиот фолдер.
Оваа едноставна, линеарна поврзаност е веројатно најбезбедна од аспект на поставување и користење подоцна од некој кој нема никакво претходно познавање. Дополнително, ваквата структура овозможува модуларност, во смисла на тоа дека секоја табела или графикон може да се ре-креира независно од остатокот на анализата, ако, на пример, нашиот соработник или рецензент сака да провери само одреден аспект на истражувањето.
6.1.3 Недостатоци
Главните недостатоци на оваа стратегија се непотребното повторување на код или податоци (не секогаш, но често), и тоа што оваа организација станува незгодна ако имаме голем или комплициран извештај со многу анализи коишто би сакале да ги одделиме.
Можното непотребно повторување да податоци веќе спомнавме погоре како разлика помеѓу недостатоците на дуплицирање наспроти предноста што копирањето на една табела на две места може да подобри леснотијата на користење. Имено, доколку некоја скрипта има соодветно именувана табела што ја користи во соодветно именуван фолдер, тогаш дури и истата табела да се јави под друго име во друг фолдер каде што се отвара од друга скрипта, тоа не создава забуна. Од друга страна, доколку истата табела, под исто име, се наоѓа во заедничи фолдер Табели, тогаш треба за двете скрипти да објасниме дека ја користат истата табела и двете скрипти треба да повикуваат табела што е сместена надвор од соодветните фолдери. Второто сценарио е малку покомплицирано, и доколку табелата во прашање е доволно мала (во смисол на меморија) тогаш од перспектива на корисник кој прв пат го гледа проектот можеби не е проблем доколку се јавува два пати.
Сепак, генералната препорака е дека најдобро е да се избегне дупликација на податоци, бидејќи податоците се (типично) најголемиот (во смисол на меморија) дел од нашиот пакет, а сакаме нашиот пакет да биде што попортабилен.
За повторувањето на програмски код имаме слична дилема. Доколку нашите табели или графици, кои ги правиме со посебни скрипти во посебни фолдери, имаат делови со идентичен код (на пример сите скрипти ги прават истите проверки за табелите, или сите скрипти за табела ја прават истата сумација по групи), тогаш можеме делот од кодот што се повторува да го изолираме во посебна скрипта што сите други скрипти ќе ја повикуваат. Оваа опција е подобра бидејќи доколку најдеме грешка или сакаме да направиме некое подобрување, тоа го правиме само во скриптата со заеднички код, додека пак доколку тој код се дуплицира во повеќе скрипти, ќе треба да ги промениме сите. Во ваков случај со изолиран заеднички код, нашата структура може да се промени во нешто налик на следниот дијаграм.
strategija_1/
├── README
├── zaednicki-kod.R
├── grafik_1
│ ├── code_grafik_1.R
│ ├── code_tabela_1.R
│ └── data_grafik_1.csv
├── grafik_2
│ ├── code_grafik_2.R
│ ├── code_tabela_2.R
│ └── data_grafik_2.csv
└── tabela_3
├── code_tabela_3.R
└── data_tabela_3.csvВториот недостаток, незгодноста кога проектот станува голем и комплициран, станува јасен со претходниот дијаграм. Кога скриптите, и фунцкии внатре во скриптите, почнуваат да стануваат зависни една од друга, предностите на линерано изолирање на кодот и податоците почнуваат да се смалуваат. На пример, ако code_tabela_3.R има функција sumiraj-po-grupi() која повикува две функции од zaednicki-kod.R и ја вчитува табелата што резултира од модулот grafik_2, тогаш немаме баш линеарна зависност туку нешто покомплицирано. И иако сеуште можеме рачно да ги организираме ваквите врски помеѓу код и податоци, веројатно е време да разгледаме други опции за организирање на нашиот проект.
6.2 Стратегија 2: Формален R пакет или некоја поедноставена варијанта
6.2.1 Структура
Разгледувајќи ја првата стратегија за организирање на повторливи проекти дојдовме до моментот кога зависностите помеѓу нашиот код и податоци почнуваа да стануваат не-линеарни. Од една страна, неколку скрипти можат да ги користат истите податоци и да повикуваат функции од една скрипта за заеднички код, од друга страна, една скрипта може да зависи од резултатите на повеќе други прекурсори. Кога нашиот проект ќе ја стигне оваа фаза, тогаш подобро е да ја напуштиме линеарната структура што изолира еден сет на податоците и нивната обработка од остатокот на пакетот и да го реорганизираме проектот така што податоците, кодот, извештате, итн, ќе бидат во засебни фолдери. Во овој случај, структурата на проектот може да биде нешто налик на следниот дијаграм:
strategija_2/
├── izvestai
├── podatoci
├── README
└── skriptiДоколку некогаш сте ја погледнале структурата на еден формален R пакет (под „формален„ мислиме пакет или библиотека која што може да се инсталира и повика со library(mojpaket)), веднаш ќе ги забележите сличностите:
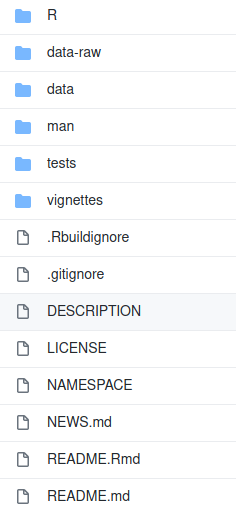
Структура на еден формален R пакет (библиотека)
Сиот програмски код е изолиран во посебен фолдер (skripti или R), податоците се во фолдери посветени на податоци (podatoci или data или data-raw), главниот директориум во двата случаи има README фајл кој ја објаснува намената на пакетот и укажува како може да се користат спакувануте компоненти, итн.
Како работиме во оваа средина? Без разлика колку скрипти имаме, со колку функции во нив, и колку комплексни се зависностите помеѓу нив:
- сите тие скрипти ги вчитуваме во нашата
Rсредина (global environment,.GlobalEnv), така што кога една фунција повикува втора функција не мора да се сетиме во која скрипта живее таа функција
- сите тие скрипти вчитуваат податоци кои се наоѓаат во
podatociи никаде на друго место
- сите тие скрипти зачувуваат продукти (табели, графици, HTML/PDF извештаи) во
izvestai
На ваков начин, ја елиминараме потрабата од копирање на податоци или код, и секоја компонента, дали е тоа изворен код или податоци, се јавува само еднаш во нашиот пакет.
6.2.2 Поставување
Поставувањето на ваков повторлив проект може повторно да оди рачно, едноставно правиме фолдери за податоци, изборен код, итн. Но исто таке можеме да искористиме постоечки функции и пакети кои го прават овој чекор полесен. Иако има многу решенија достапни решенија, ќе тука ќе споменеме две опции. Прво, можеме да ја искористиме функционалноста за креирање формални R пакети, дури немаме намера да го објавуваме нашиот пакет. Кодот користи два пакети кои до сега не сме ги спомнале (devtools (Wickham, Hester, and Chang 2020) и usethis (Wickham and Bryan 2020)), но е едноставен:
library(devtools)
library(usethis)
devtoos::create(path = "mojpaket")
podatoci1 <- read.csv("~/Desktop/moi-podatoci.csv")
usethis::use_data("podatoci1")Извршувањето на горните линии ќе креира структура налик на следната:
mojpaket/
├── DESCRIPTION
├── NAMESPACE
├── data
└── RПонатаму, како додавате документација, вињети, или тестови, можете да генерирате соодветни фолдери полу-автоматски. За далеку повеќе детали околу овие процедури, ве повикуваме да ја погледнете книгата за R пакети од Хадли Викам ((Wickham 2015)).
Втората опција за креирање на ваква структура за повторлив проект е преку користење на пакети посветени кон токму тоа: да олеснат повторливи анализи/истражувања/извештаи преку автоматизирање на некој од компонентите на повторливост кои ги дискутиравме до сега. Има повеќе вакви пакети: prodigenr, makeProject, ProjectTemplate, fertile, goodpractice, итн кои специјализираат кон различни аспекти (дали структура на проектот, проверки на кодот, итн). Овде, накратко, ќе се запознаеме со основната функционалност на пакетот prodigenr (Johnston 2019) кој овозможува креирање на структура налик на формален R пакет но без (понекогаш непотребниот) багаж кој доаѓа со развивањето и користењето на еден формален R пакет.
Потоа, доколку го погледнеме направениот проект ја имаме следната структура:
mojproekt2/
├── data
│ └── README.md
├── DESCRIPTION
├── doc
│ └── README.md
├── mojproekt2.Rproj
├── R
│ ├── fetch_data.R
│ ├── README.md
│ └── setup.R
├── README.md
└── TODO.mdНа пример, скриптата setup.R доаѓа со објаснување како да ги организираме нашите скрипти/функции со цел да бидат достапни за време на интерактивната сесија. Додека пак скриптата fetch_data.R не насочува кон тоа како да ги собираме и подготвиме табелите со податоци за зачувување во data/ и понатамошно користење. Како и во еден формален пакет, фајлот DESCRIPTION дава инструкции за зависностите на нашиот код (не-стандардни R пакети). Како и секогаш, ве покануваме да ја прочитате документацијата на пакетот (на пример library(help="prodigenr")) за повеќе детали.
6.2.3 Предности
Очигледно има добри причини зошто би сакале нашиот повторлив проект да има структура слична на формален R пакет. Еден R пакет може да се инсталира и користи без проблем на било кој компјутер, има ефективна документација со вградени упатства за употреба и подолги вињети за специјални случаи, има екплицитно менаџирање на зависностите, и единични тестови (unit tests) кои што проверуваат дали секоја фунцкија го дава очекуваниот резултат во различни контексти.
6.2.4 Недостатоци
Може да се најдат недостатоци во било кој систем, и секако оваа структура може сеуште да се подобрува, но за робустна организација на вашите повторливи проекти веројатно треба да се држите до некоја од алтернативите дискутирани тука. Она што може да се спомене, не како недостаток, туку предупредување, е дека навинкувањето и целосно искористување на ова структура ќе бара малку повеќе време и учење, како за оној кој го подготвува проектот така и за корисниците.
6.3 Резиме
Без разлика која од овие опции ви ваќа повеќе око, или е поадекватна за вашиот проект, она што навистина прави разлика е внимание, трпение, и дисциплина при поставувањето на структурата на проектот и следењето на најдобрите пракси за повторливо програмирање. Дури и да имате идеална структура за вашиот проект, тоа нема да значи ништо доколку на вториот работен ден почнете да пишувате скрипти без документација или почнете да зачувувате фајлови во главниот фолдер наместо во посветените фолдери. Не се изненадувајте доколку следејќи ги праксите кои ги дискутираме тука текстот кој го пишувате за да документирате како работи одредена скрипта е подолг од самата скрипта што ја објаснувате.
Литература
Johnston, Luke. 2019. Prodigenr: Research Project Directory Generator. https://CRAN.R-project.org/package=prodigenr.
Wickham, Hadley. 2015. R Packages: Organize, Test, Document, and Share Your Code. " O’Reilly Media, Inc.".
Wickham, Hadley, and Jennifer Bryan. 2020. Usethis: Automate Package and Project Setup. https://CRAN.R-project.org/package=usethis.
Wickham, Hadley, Jim Hester, and Winston Chang. 2020. Devtools: Tools to Make Developing R Packages Easier. https://CRAN.R-project.org/package=devtools.